if podmínka příkazy end
Řetězce neboli pole znaků, (anglicky character arrays nebo strings) jsou v podstatě vektory, které obsahují znaky anglické abecedy. Nedoporučuje se používat české znaky obsahující háčky nebo čárky, protože bývá problém s jejich správným zobrazováním.
Pro vytvoření řetězce slouží apostrofy, do kterých se vepíše obsah řetězce (například 'ahoj' nebo 'Toto je nejaky dlouhy text.'), přičemž takto vytvořený řetězec můžeme uložit do proměnné:>> s1 = 'nejaky text';
>> nazev = 'Vypocetni technika 2'
Ve workspace se řetězec objeví jako proměnná typu char array (doposud jsme znali jen čísla - double array).
Poznámka: řetězce lze ukládat i do matic, ale je nutné, aby všechny řádky (= řetězce) měly stejnou délku! Doplňuje se většinou mezerami, tedy:
>> jmena=['Ivan '; 'Jana '; 'Ludva'; 'Eva '; 'Pepa '];
Pokud máme řetězec uložený v nějaké proměnné, můžeme jej vypsat úplně stejným způsobem jako obsah kterékoli číselné proměnné, tedy zadáním jména proměnné (například >> s1).
Existují také funkce, které vypisují zadaný řetězec, a to funkce disp(p1), která má jeden parametr (je označen jako p1). Parametrem může být text nebo název proměnné:
>> disp('ahoj')
>> disp(s1)
a funkce error(p1), jejímž parametrem je chybové hlášení (vypisuje se červeně). Tato funkce navíc ukončuje provádění aktuálního příkazu (proto se používá uvnitř funkcí a skriptů).
Poznámka: práce s řetězci
Jelikož je řetězec vektor složený ze znaků, můžeme s ním pracovat znak po znaku. Jinou možností je využít knihovních funkcí MATLABu, které nabízejí porovnávání řetězců (např. funkcestrcmp), převod na velká nebo malá písmena (upperalower), konverze řetězců na čísla a naopak (např.str2numanum2str),... Více se můžete dozvědět z nápovědy k jednotlivým funkcím - jejich přehled získáte příkazem>> help strfun.
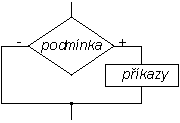
Občas potřebujeme, aby se určité příkazy vykonaly jen a pouze v případě, kdy je splněna nějaká podmínka. Bylo by tedy dobré znát nějaký příkaz, který umožňuje podmínku vyhodnotit (otestovat), a podle její pravdivosti pak vykoná (nebo nevykoná) zadanou množinu příkazů. V MATLABu máme k dispozici příkaz if. Jeho základní syntaxe je:
if podmínka příkazy end
Příkaz začíná klíčovým slovem if, za nímž následuje podmínka - to je libovolný výraz s logickou hodnotou 0 nebo 1 (většinou se v podmínkách používají relační nebo binární logické operátory). Uvnitř ifu jsou jakékoli příkazy, které se mají provádět v případě splnění podmínky. Protože příkazů uvnitř ifu může být více, tak za posledním z nich musíme uvést klíčové slovo end, které označuje konec celého příkazu.
Činnost příkazu if: nejprve se testuje podmínka (tj. vypočítá se hodnota výrazu) a v případě, že podmínka platí (je pravdivá; tj. výraz má logickou hodnotu 1, neboli je nenulový), jsou provedeny příkazy uvnitř ifu. V opačném případě, kdy podmínka neplatí (není splněna, tj. výraz má logickou hodnotu 0, tj.je nulový), příkazy uvnitř ifu jsou ignorovány a pokračuje se až za koncem příkazu if (pokud jsou za ním nějaké další příkazy). Činnost příkazu demonstruje vývojový diagram:
if podmínka příkazy end |
|
if se mohou vnořovat, tj. uvnitř ifu může být další příkaz if.
Příklad 1 - chtěli bychom vypsat gratulaci jen v tom případě, kdy žák bude mít jedničku. Vyzkoušíme si to nejprve pro trojku, tedy v Command Window zadáváme:
>> znamka=3;
>> if znamka==1
zprava='Gratuluji! Lepsi to byt nemohlo!'
end
Všimněte si:
- po zadání části příkazu if MATLAB čeká na jeho dokončení (nevypisují se znaky >>)
- protože proměnná znamka neobsahovala číslo 1, tak podmínka neplatí - proto se proměnná zprava nevytvořila.
Nevýhoda:
pokud bychom chtěli vyzkoušet stejný příkaz pro jinou známku, musíme všechno napsat znovu, přičemž první příkaz opravíme na >> znamka=1;. Je vidět, že práce v Command Window se v případě složených příkazů stává neefektivní. Máme sice možnost napsat celý if na jeden řádek (příkazy od sebe musíme oddělit - čárkou nebo středníkem), ale tím si celou situaci znepřehledníme:
>> znamka=1; if znamka==1; zprava='Gratuluji! Lepsi to byt nemohlo!', end
Proto se v dnešní lekci naučíme vytvářet skripty (soubory s posloupností příkazů) a funkce (soubory se specifickou strukturou, které mohou zpracovávat vstupní parametry). Následující příklady budou psány tak, jako kdyby se vyskytovaly uvnitř skriptu nebo funkce.
Příklad 2 - v případě, že proměnná a je menší než pět, vypíšeme zprávu, jinak se nic neprovede:
if a < 5
disp('cislo 'a' je mensi nez 5')
end
Pro případ, kdy potřebujeme provést nějaké příkazy v případě platnosti podmínky, ale jiné příkazy v případě její neplatnosti, můžeme použít větev else:
if podmínka1 příkazy1 else příkazy2 end |
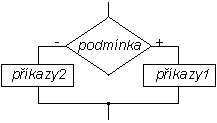 |
if-else: nejprve se testuje podmínka - je-li pravdivá, provedou se příkazy1, je-li nepravdivá, provedou se příkazy2. Vždycky se tedy provede jedna skupina příkazů.
Příklad 3 - v případě, že proměnná a je menší než pět, vypíšeme zprávu "a je mensi", jinak se vypise "a je vetsi nebo rovno":
if a < 5
disp('cislo 'a' je mensi nez 5')
else
disp('cislo 'a' je vetsi nebo rovno 5')
end
Z příkladu 3 je vidět, že někdy by bylo vhodné v případě neplatnosti podmínky testovat také jiné možnosti. Ke splnění tohoto cíle stačí vnořit další příkaz if do větve else, ale existuje pohodlnější prostředek - rozšířená syntaxe příkazu if:
if podmínka1 příkazy1 elseif podmínka2 příkazy2 else příkazy3 end |
|
if obecně: nejprve se testuje pravdivost podmínky1. Pokud platí, provedou se příkazy1 a ostatní větve příkazu jsou ignorovány. Pokud podmínka1 neplatila, začne se testovat podmínka2 - když platí, provedou se příkazy2 a zbylé větve jsou ignorovány; neplatí-li, pokračuje se další větví elseif (je-li ještě nějaká)... V případě, že ani jedna z podmínek neplatila, jsou provedeny příkazy ve větvi else (je-li přítomna).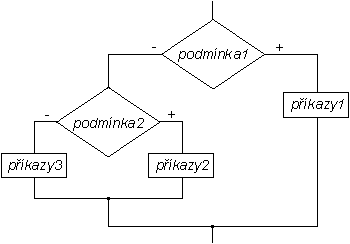
Příklad 4 - chceme rozhodovat o poloze hodnoty proměnné a vzhledem k číslu 5:
if a < 8
disp('a je mensi nez 5')
elseif a > 8
disp('a je vetsi nez 5')
elseif a == 8
disp('a je rovno 5')
else
error('Nedefinovaná situace!')
end
M-soubory slouží k ukládání posloupností příkazů (skripty) nebo k ukládání uživatelských funkcí (funkce).
Poznámka: M-soubory jsou obyčejné textové soubory, a proto je lze psát i v libovolném textovém editoru. Z důvodu vyššího komfortu (zvýraznění syntaxe, možnost krokování) je však součástí MATLABu také M-editor/Debugger, který se otevírá v samostatném okně po otevření nebo vytvoření M-souboru (skriptu či funkce).
M-editor/Debugger je spuštěn v samostatném okně po otevření (File Open) nebo vytvoření (FileNewM-file) M-souboru. Slouží k pohodlné editaci M-souborů. Navíc umožňuje krokovat obsah M-souborů (tj. kontrolovat provádění jejich jednotlivých příkazů).
Open) nebo vytvoření (FileNewM-file) M-souboru. Slouží k pohodlné editaci M-souborů. Navíc umožňuje krokovat obsah M-souborů (tj. kontrolovat provádění jejich jednotlivých příkazů).
Skript je posloupnost příkazů uložených do souboru. Každý skript pracuje s proměnnými pracovního prostředí, takže může vytvářet nové nebo mazat či měnit vybrané. Výsledky skriptu tedy zůstávají v pracovním prostředí i po jeho skončení. Skripty samozřejmě mohou volat jiné skripty nebo funkce, vytvářet grafická okna, vypisovat do Command Window,...
Poznámka: V době psaní skriptu se jeho příkazy samozřejmě neprovádějí - k tomu potřebujeme spustit skript v Command Window (viz Spuštění skriptu).
NewM-file, čímž se také otevře okno M-editoru/Debuggeru. Pokud chceme opravit již existující skript, musíme jej otevřít (například pomocí menu FileOpen).Save, kde zkontrolujeme pracovní adresář a zadáme jméno skriptu:Spuštění skriptu dává MATLABu pokyn k vykonání jeho příkazů. Před spuštěním musí být skript uložen! Skript můžeme spustit buď
>> jméno, tj. skript graf1.m spustíme příkazem >> graf1), anebo
Run (klávesa F5).
Příklad - vytvoříme skript parabola.m, který kreslí graf funkce x2:
| parabola.m |
% GRAF1 - vykresleni parabolyx = -3:0.1:3; % vektor hodnot z intervalu [-3;3] s krokem 0,1y = x.^2; % zavisle promennaplot(x,y) % graf (parabola) |
>> parabolaObsah skriptu (M-souboru) vidíme v M-editoru/Debuggeru, ale můžeme jej zobrazit také v Command Window příkazem >> type název, kde název je jméno skriptu (název M-souboru bez přípony).
Máme-li používat jeden určitý postup (algoritmus) pro vícero různých situací (např. pro různé hodnoty proměnných), není zrovna praktické používat skripty, neboť pokaždé musíme opravit hodnoty proměnných ve skriptu, uložit příslušný M-soubor a skript spustit. Řešení nabízejí funkce.
Funkce jsou M-soubory, které mají přesně definovanou strukturu (viz Vytvoření funkce). Funkce akceptují vstupní parametry, které mohou mít při každém spuštění jinou hodnotu.
Každá funkce má své vlastní pracovní prostředí, které je odděleno od pracovního prostředí Command Window. Všechny proměnné ve funkci jsou lokální (existují jen po dobu spuštění funkce)! To znamená, že:
NewM-file. Tím se otevře okno M-editoru/Debuggeru s prázdným souborem.Open.function | [výstupy]= | jmeno_funkce | (vstupy) | |
 | | | | |
| klíčové slovo | výstupy funkce | název funkce | vstupní parametry funkce |
výstupy:jmeno_funkce:vstupy:function [s]=soucet(a,b) - funkce s jedním výstupem a dvěma vstupyfunction[podil,zbytek]=deleni(delenec,delitel) - funkce se dvěma vstupy i výstupyfunction f=faktorial(n) - funkce s jedním výstupem i vstupemfunction graf(x,y) - funkce bez výstupu, s jedním vstupem>> help jméno_funkce, stejně jako nápovědu ke knihovním funkcím MATLABu.>> lookfor slovo (slouží pro výpis všech funkcí obsahujících dané slovo) nebo při výpisu nápovědy k funkcím nějakého adresáře >> help adresář (například >> help C:\temp\matlab).error, jejímž parametrem je text chybového hlášení (např. error('Chyba: mnoho vstupních parametrů!'))
function [s]=soucet(a,b) |
s stačífunction [prep]=prepona(odvesna1,odvesna2) |
Save, kde:
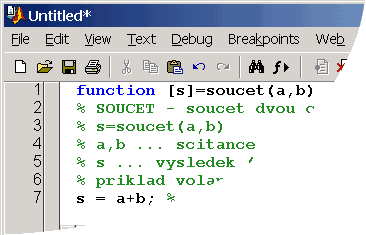 Obr. 2: zatím neuložená funkce v M-editoru |
 Obr. 3: uložená funkce v M-editoru |
Pokud jsme vytvořili vlastní funkci, můžeme ji spustit z Command Window (anebo z jiných funkcí či skriptů). Příkaz pro spuštění funkce vypadá obecně takto:
>> [vystupy]=jmenofce(vstupy), pokud chceme uložit výsledky do nějakých proměnných (na konci lze uvést středník, aby se výsledky nevypisovaly), nebo takto:
>> jmenofce(vstupy), pokud nechceme výsledky ukládat do proměnných.
Poznámky:
nargin)
ans)
nargout mohou vracet různé výsledky v závislosti na počtu právě odebíraných výstupů)
>> help jmenofce)
>> clear all)
Příklady:
>> s=soucet(7,14); s odebráním výstupu a bez jeho výpisu
>> vysledek=soucet(7,14) s odebráním výstupu i jeho vypsáním
>> x=7; y=14; soucet(x,y) bez odebrání výstupu, ale vypsáním výsledku (pomocí ans)
>> soucet(3.1,8.14) bez odebrání výstupu, bez vypsání výsledku (v podstatě zbytečná akce)
Pokud chceme vědět, jak funkci spustit nebo jak pracuje (a funkce byla vyvtořena s nápovědou), můžeme použít příkaz >> help jmenofce, kde jmenofce je název M-souboru bez přípony.
Jinou možností je pak napsat jméno funkce (v Command Window nebo v M-editoru/Debuggeru), označit ho (třeba dvojklikem myši) a pomocí pravého tlačítka myši zobrazit kontextové menu, kde zvolíme položku "Help on selection" (otevře se Help Browser s nápovědou k funkci; tato nápověda vypadá u knihovních funkcí lépe než při použití příkazu help).
Kód funkce (tj. obsah M-souboru) vidíme v M-editoru/Debuggeru, ale můžeme jej zobrazit také v Command Window příkazem >> type jmenofce, kde jmenofce je název funkce (název M-souboru bez přípony).
Pokud chceme, aby naše funkce reagovala na různý počet vstupních parametrů, můžeme v jejím kódu použít nargin. Funkce nargin nemá žádné vstupy, ale vrací skutečný počet parametrů, s nimiž byla funkce spuštěna. Pokud tedy někdo zavolá naši funkci s menším počtem vstupních argumentů, můžeme je zpracovat jinak než v případě plného počtu vstupů.
Pozor: pořadí vstupních parametrů v definici funkce je zavazující (tedy pokud si myslíme, že vynecháme druhý ze čtyř vstupů, funkce to pochopí tak, že jsme vynechali ten čtvrtý!).
Pro zjištění skutečného počtu výstupních parametrů máme funkci nargout. Pracuje se s ní podobně jako s funkcí nargin.
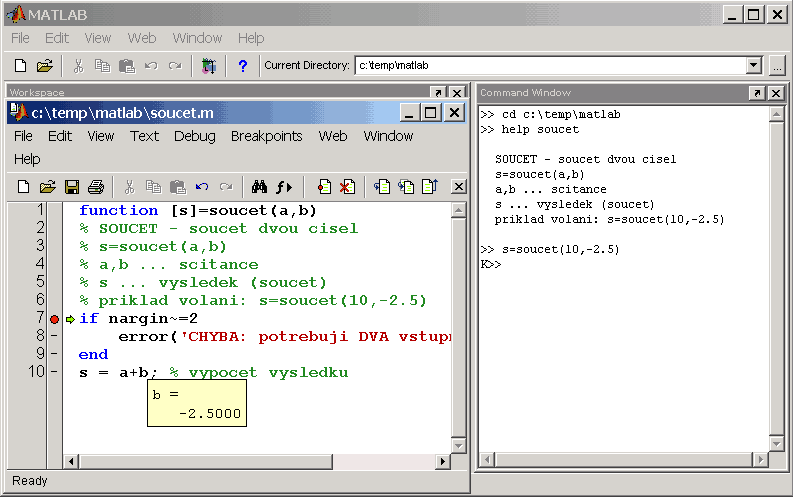
Příklad - vylepšíme funkci soucet, aby sama hlásila chybu, když ji někdo zavolá pro méně než dva parametry:
| soucet.m |
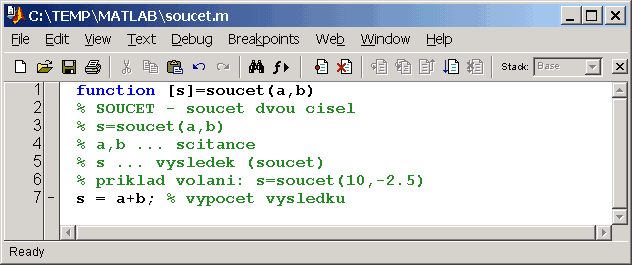
function [s]=soucet(a,b)
% SOUCET - soucet dvou cisel
% s=soucet(a,b)
% a,b ... scitance
% s ... vysledek (soucet)
% priklad volani: s=soucet(10,-2.5)
if nargin~=2 % nespravny pocet vstupu?
error('CHYBA: k vypoctu potrebuji DVA vstupy!') % vypis chyby a konec funkce
end % konec if
s = a+b; % vypocet vysledku
|
Pokud jsou ve funkci chyby (např. nedává správné výsledky) a nemůžeme jejich příčinu najít pouhým přečtením jejího kódu, použijeme Debugger ("odvšivovač"), který nám nabízí možnost krokování:
K>> a v M-editoru svítí zelená šipka před řádkem, který bude následně zpracován
Hesla semestru: